Research 2017 scientific & technological
The best site search engines used today have flaws and lack certain features which make them difficult to use effectively. They aren’t intuitive enough to understand what the searcher is looking for and can often return empty or irrelevant results.
Search engines do not use Artificial Intelligence to learn about the search keywords and related concepts to return relevant results when there are no exact query matches within the database. If the user doesn’t know the exact word for what he’s searching for, traditional search engines won’t return the desired search results. Additionally, these search engines can only learn search parameters from pre-existing knowledge and data. If that data is lacking, the search won’t successfully operate.
Search3w developed the Cognitive Artificial Intelligence (CAI) 1 search engine for smart search within a website which would return results that are cognitively relevant if there are no exact matches to the search query within the local web site database. Prior to beginning this project, the Search3w Research team tried to use the AI approaches and cloud models developed by Yahoo, Google and Amazon. However, those models work only if they’ve been previously trained on the existing data sets2.
As a result, those models cannot be used if the existing data sets are missing information relevant to search engine queries, or ignoring new products that have been added to the inventory. It was uncertain whether implementing a more intuitive search engine would actually return results that are cognitively relevant if there were no exact matches to the search query within the local web site database. Knowledge about how to implement such search methodology did not exist prior to beginning this project.
The Cognitive Artificial Intelligence Project
The team hypothesized that when there were no exact matches to the search query within the local website database, to learn about the meaning of the keyword (subject of the search) and cognitively relevant products/subjects that most closely matches the attributes of the original subject, the search engine would check the artificial intelligence database that contains the subjects cognitively relevant to the original subject through their features.
If results are found in this dictionary, an array of the keywords from the database describing the subject with the same or similar attributes would be used to repeat the search queries within the local web site database. If no results are found in the dictionary, the search engine would call web APIs to extract details about the searches relevant to the subject in question and learn about features of this subject by breaking the results into small pieces and analyzing them (e.g. toilet paper is smooth, usually white and has a shape of cylinder).
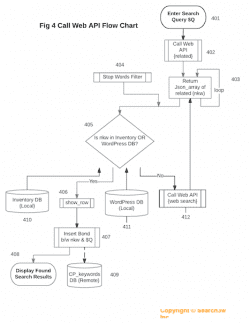
Web API Flow Chart
After that, the search engine would make an assumption about most relevant keywords extracted from the web, add them to the dictionary, and use them to repeat the search within the local website database (e.g. show me all items with a cylinder shape). The research team hypothesized that the search engine does not require the machine the search query through the artificial intelligence component.
After extensive experimentation, the team developed the first experimental prototype of the Cognitive Artificial Intelligence (CAI) search engine. This prototype did not include the machine learning component for search engine training.
Next, to track users behaviour and to improve the performance of the search engine by minimizing web API calls, the research team decided to introduce the machine learning component. It was decided to present the subjects supposedly relevant to the original search query that were found through fuzzy search to the users so that they could select the keyword which is best matches the original subject.
Once the user selects a keyword, the search engine establishes a link between the original search keyword and the keyword that the user selected. Through those neuron links, originally discovered by fuzzy search and verified by the user, which are stored in the machine learning database, the search engine learns about relationships (“neuron network”) between different subjects and their attributes. Next time the search engine has to perform a search query for the same keyword and the same user, it would not have to perform a web search to find cognitively relevant products/subjects that most closely matches the attributes of the original subject. It was discovered through experimentation that the developed experimental prototype of the Cognitive Artificial Intelligence (CAI) search engine works well on small-scale inventory, up to 30,000 items (or 30,000 web pages) and starts to slow down as more records are added into the database. The team hypothesized that a search engine could be migrated to NoSQL database and distributed computing “big data” architecture8. By the end of the year, the team was still experimenting with this approach. The project is ongoing.
What work did you perform in 2017 to overcome the scientific or technological uncertainties?
The research team achieved a technological advancement through developing a concept of the Cognitive Artificial Intelligence (CAI) search engine. The developed concept of the cognitive search was based on cognitive learning methodology used for recognizing users’ query intentions. The developed CAI search engine allows smart search within a website that returns cognitively relevant results if there are no exact matches to the search query within the local web site database. New knowledge in the area of computer science was generated that allowed the development of a search methodology that would return cognitively relevant results if there are no exact matches to the search query within the local web site database. The developed search methodology did not require models previously trained on the existing data sets.
NextAI
This research project was accepted to be finalist in Ontario’s NextAI innovation venture because CAI (Cognitive Artificial Intelligence) will make a huge impact with the devices that require an agile response as it flexes itself to the user and not the user needs to flex himself to the machine (e.g. if SIRI answer makes no sense, one needs to rephrase it). Specifically, just to mention one implementation, the plan is to fix these devices that can understand people with a speech disability and implement it within the Smart Cities project.
Reference
- IBM, Artificial Intelligence, Machine Learning and Cognitive Computing
- Big Data https://www.mongodb.com/big-data-explained
- Google Algorithm and Axiomatic Set Theory
- AI https://www.search3w.com/googles-rankbrain-is-an-old-hat-artificial-intelligence-machine/
- Patent #US8990066 – Resolving out-of-vocabulary words during machine translation
- Patent #US8527262 – Systems and methods for automatic semantic role labeling of high morphological text for natural language processing applications
- Patent #US7409334 – Method of text processing
- About NOSql – https://www.mongodb.com/nosql-explained


